
Auf Twitter ist neulich der Tipp rumgegangen, man solle doch gefälligst ein Archiv seiner Daten herunterladen. Wie genau diese Idee entstanden ist, konnte ich nicht verifizieren. Rechnen die Leute damit, dass dort demnächst alles in Flammen aufgeht?
Oder ist es eine subtile Massnahme, um den neuen Chef unter Druck zu setzen? Denn natürlich ist im Hauptquartier des Unternehmens ersichtlich, wenn plötzlich Zehn- oder Hunderttausende Nutzer ihr Archiv anfordern. Das kann nur als Alarmzeichen gewertet werden. Denn es beinhaltet die Drohung, dass viele Leute sich für den Absprung bereit machen.
Ich gedenke nicht, Twitter den Rücken zu kehren. Mich nervt Elon zwar auch, aber ich will den Gang der Dinge vor Ort verfolgen – und die sich auf meine Lust, mich einzubringen, auswirkt, bleibt abzuwarten. Dennoch habe ich die Gelegenheit wahrgenommen, mein Twitter-Archiv herunterzuladen. Ich finde die Datenfreizügigkeit eine gute Sache und ich schaue mir auch ganz gern an, in welcher Form die Daten denn tatsächlich ausgeliefert werden. Das verrät ein bisschen etwas über die technischen Interna. Und wir könnten uns überlegen, was wir mit diesen Daten anstellen könnten – wenn wir denn die Zeit dazu hätten.
Anfordern und abwarten
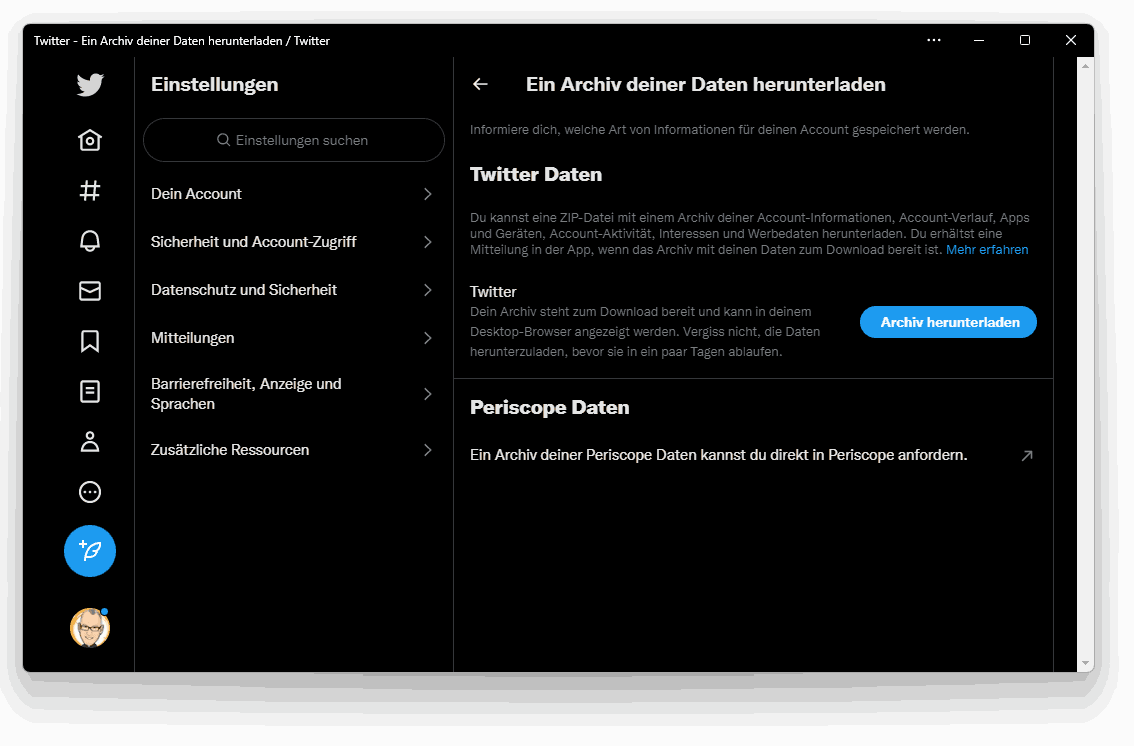
Also, wir fordern diese Daten bei Twitter über den Knopf Mehr in der Navigation an. Wir klicken auf Einstellungen und Support, dann auf Einstellungen und Datenschutz und finden in der Menüauswahl Dein Account den Punkt Ein Archiv deiner Daten herunterladen vor. Wenn wir den anklicken, müssen wir uns noch einmal mit unserem Passwort ausweisen. Dann fordern wir die Daten an, woraufhin sie auf dem Server in eine Archivdatei verpackt werden. Übrigens: Auch die Daten von Periscope, dem gescheiterten Kurzvideodienst von Twitter, können über einen Link angefordert werden.
Die Bereitstellung dauert seine Zeit: In meinem Fall war das Archiv nach gut zwei Tagen verfügbar. Wir werden per E-Mail darüber informiert, wenn es parat ist und können es (wiederum nach einer Extra-Verifzierung) herunterladen.
Alle Tweets? Nein, nicht ganz

In meinem Fall ist das Archiv 200 Megabyte gross. Entpackt, finden wir im Wurzelverzeichnis die HTML-Datei Your archive.html vor, die das Archiv wohl erschliessen sollte. In meinem Fall bleibt die Seite einfach leer. Aber das soll uns nicht daran hindern, das Archiv manuell zu durchforsten.
Wir finden die eigentlichen Tweets in der Datei data\tweets.js. Dass sie die Endung für JavaScript trägt, ist irritierend, aber die Datenstruktur erschliesst sich sofort: Nebst dem Text eines Tweets (Variable full_text) finden wir auch Angaben zu den Anzahl Favoriten (favorite_count), Retweets (retweet_count) und den Veröffentlichungszeitpunkt (created_at). Bei einer Antwort gibt es auch die Informationen, auf welchen Tweet sie sich bezieht und wem geantwortet wurde.
Natürlich ist auch die Tweet-ID vorhanden (ID): Mit der finden wir den Tweet auf der Twitter-Website, wenn wir die Adresse https://twitter.com/[Twitter-Name]/status/[ID] eingeben.
Tweets, die Twitter als heikel einstuft
Sofort ins Auge gesprungen ist mir die Variable possibly_sensitive: Sie gibt an, ob der Tweet heikel sein könnte. Bei den meisten meiner Tweets weist sie den Wert false auf, also unverdächtig. Aber natürlich machen wir uns sofort den Spass, im Archiv nach dieser Zeichenfolge zu suchen:
"possibly_sensitive" : true
Leider muss ich an dieser Stelle vermelden, dass keiner meiner Tweets als «possibly sensitive» markiert ist und ich darum keine sachdienlichen Erkenntnisse zu dieser Angelegenheit vermelden kann.
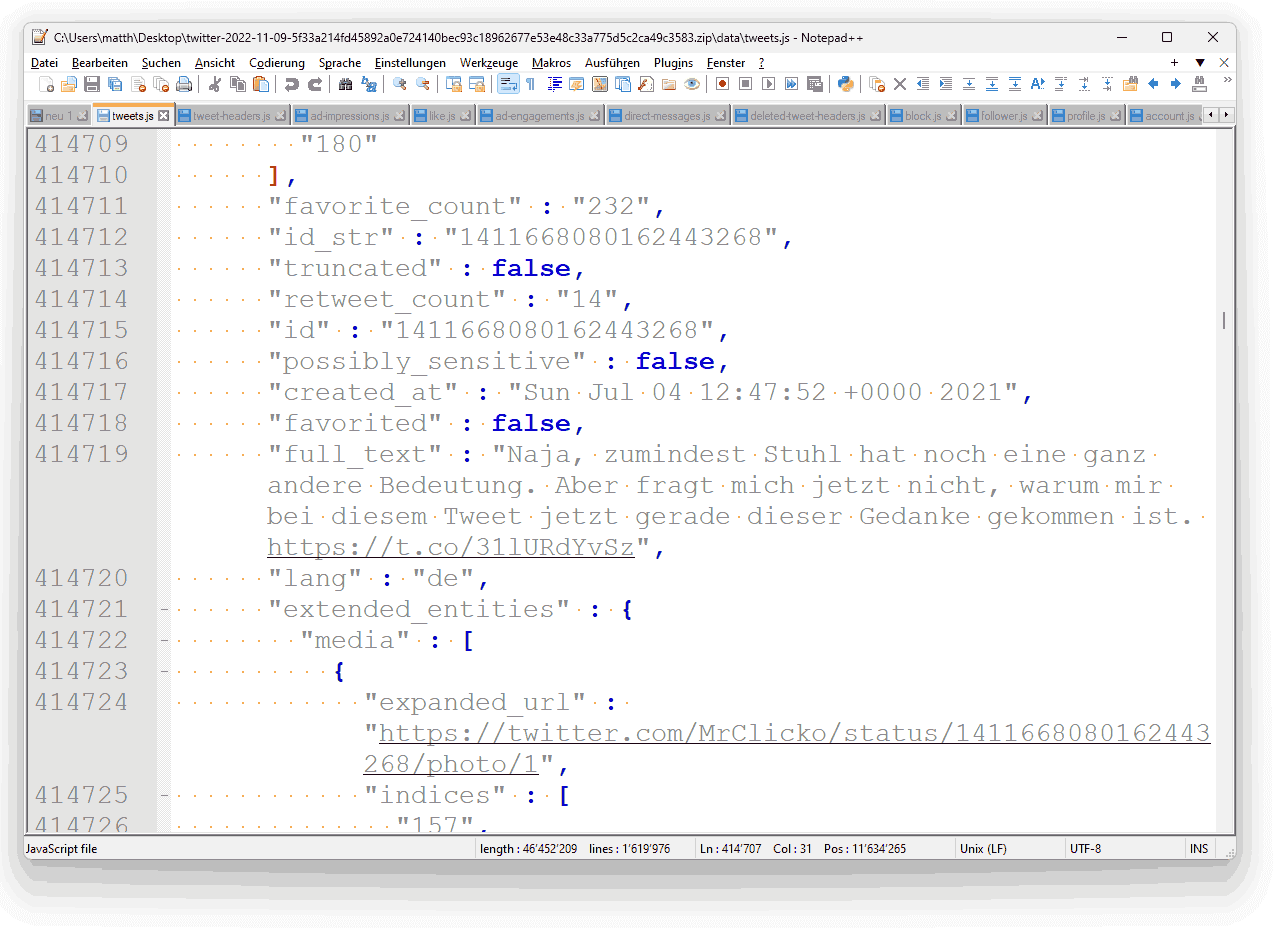
Ein Problem gibt es mit dieser Datei: Sie ist nicht vollständig. Mein Archiv geht bis zum 6. August 2012 zurück, beigetreten bin ich aber schon am 14. Januar 2009.
Noch ein paar weitere Einsichten zu diesem Archiv:
- In der Datei tweet-headers.js stecken die ID und das Datum der Veröffentlichung, nicht aber der Inhalt des Tweets. Aber aus dieser Datei liesse sich einfach eine Liste aller Tweets mit Links zu den Original-Tweets basteln.
- Unter ad-impressions.js sehen wir, welche Werbung uns angezeigt wurde und wie sie getargeted war. Das ist eine echte Fundgrube! Ich sehe zum Beispiel, dass ein Investment-Unternehmen mich als Follower look-alikes von @nytimes identifiziert hat. Mit anderen Worten: Ich sehe aus wie einer, der der «New York Times» folgt und darum ins Kundenprofil für gewisse Geldanlagen falle. Auch interessant: Glencore adressiert die Elon-Musk-Folger (Follower look-alikes: Elon Musk).
- Die Werbung, mit der wir irgendwie interagiert haben, steckt unter ad-engagements.js.
- Die Direktnachrichten sind auch vorhanden, nämlich in der Datei data\direct-messages.js.
- Wir sehen, welche Tweets wir gelöscht haben. Die stecken in der Datei deleted-tweet-headers.js, aber ohne Inhalt – darum annähernd nutzlos.
- Unter like.js finden sich die vergebenen Likes.
- Unter data\block.js erfahren wir, welche User wir blockiert haben – leider ohne Datum, wann wir die Blockierung eingerichtet haben.
Und so weiter: Es gibt auch Dateien für die Follower (follower.js) und Gefolgten (following.js), die abgespeicherten Suchläufe (saved-search.js), Stummschaltungen (mute.js), zum Account (account.js) und Profil (profile.js), zu den abonnierten Listen (lists-subscribed.js), zu unseren eigenen Listen (lists-created.js) und zu den Listen, auf denen wir vertreten sind (lists-member.js).
Videos und Fotos sind vorhanden – die Listen nicht
Die Bilder und Videos, die wir unseren Tweets angehängt haben, stecken im Ordner data\tweets_media; leider mit einem nur schwer zu deutenden Dateinamen – eine ID, die keine Auskunft über das Datum der Veröffentlichung gibt. Auch die per Direktnachricht ausgetauschten Bilder und Videos finden wir vor, nämlich im Ordner direct_messages_media.
Das macht einen annähernd vollständigen Eindruck. Was ich nicht gefunden habe, ist der Inhalt der Listen, die wir erstellt haben: Die scheint nicht ausgeliefert zu werden, was schade ist. Es würde es ermöglichen, die Listen auf einer Dritt-Website zu veröffentlichen.
Es bleibt aber dabei: Diese Datenarchive sind eine tolle Sache! Es steckt eine Menge Informationen in ihnen, die uns auf dem Dienst selbst nicht angeboten werden. Und eben: Wir haben ein Archiv unserer Twitter-Historie, das wir lokal speichern können und das uns niemand wegnehmen kann. Das grosse Manko besteht darin, dass nur immer unsere Seite der Konversation enthalten ist – darum lassen sich Diskussionen aus diesem Offline-Speicher nicht vollständig reproduzieren.
Beitragsbild: Twitter-Vogel mit Rucksack (Dall-e 2).