
Anfang April habe ich das perfektionistische Ende eines überambitionierten Projekts verkündet. Und mich offensichtlich in mir selbst getäuscht. Denn wie sich zeigt, bin ich in der Lage, eine Sache auch weit über ihren gottgewollten Endpunkt hinaus zu treiben.
Also, es handelt sich um mein Projekt 2020, das Mitte 2022 nun hoffentlich endgültig so ausgereift ist, dass sogar mir nichts mehr einfällt, was ich verbessern könnte.
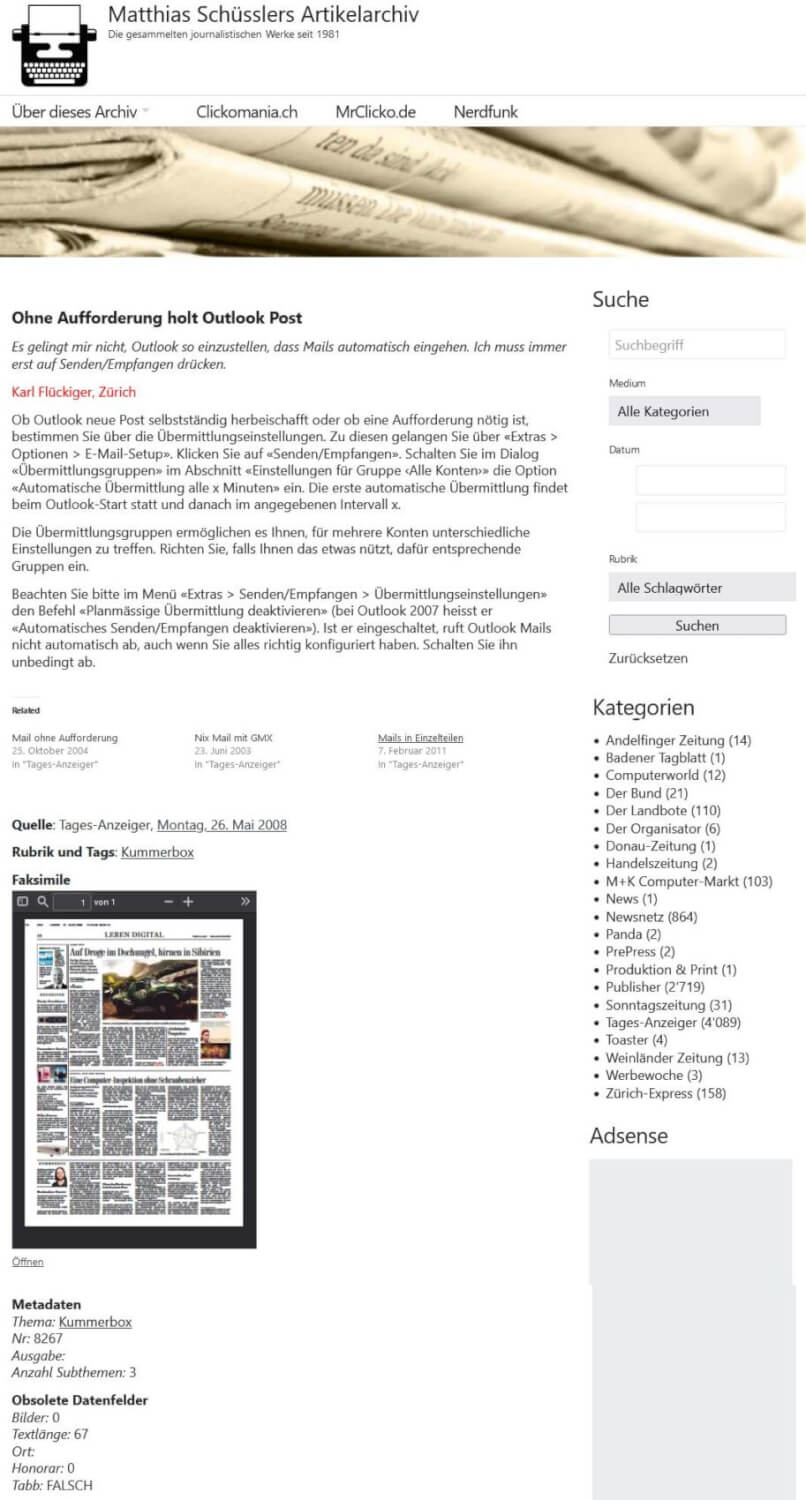
Dieses Projekt bestand darin, eine in Microsoft Access gespeicherte Datenbank web- und zukunftstauglich zu machen. In der Datenbank, die ich seit 1992 pflege, sind meine in diversen Medien erschienen Artikel im Volltext und mit einigen Metadaten erfasst. Ich habe einige Dinge ausprobiert und mich dann entschieden, die Daten mittels WordPress online zu erschliessen – was sich als hervorragende Wahl entpuppt hat.
Nachdem das Projekt eigentlich abgeschlossen war, hat mich eine Sache nicht in Ruhe gelassen: Nämlich die Tatsache, dass ich in der Access-Datenbank die Artikel als Nur-Text erfasst hatte – also ohne jegliche Formatierungen und vor allem ohne Links. Ich habe zwar ungefähr ab 1999 die Artikel auch als HTML-Seiten archiviert, sodass ich diese online deponieren und verlinken konnte. Aber mit dieser Methode war für die formatierte Ansicht ein Extra-Klick notwendig.
Bloss ein unbedeutender Schönheitsfehler
Vernünftige Leute wären überzeugt, dass ein kleiner Zusatzschritt keine Tragödie darstellt. Aber falls ihr auch eine perfektionistische Ader habt, dann kennt ihr das vielleicht: Ihr kommt einfach nicht über ein Manko hinweg, selbst wenn das objektiv gesehen nur einen unbedeutenden Schönheitsfehler darstellt.

Weil ich so ein detailverliebter Mensch bin, habe ich mir überlegt, wie man die unformatierten Datenbankeinträge durch ihr HTML-Äquivalent ersetzen könnte.
Das wäre keine grosse Sache, wenn es eine 1:1-Beziehung zwischen HTML-Dateien und Datenbankeinträgen geben würde. Das ist aber leider nicht der Fall. Es gibt viel mehr Datenbankeinträge als HTML-Dateien. Beispiel Kummerbox: Bei dieser Rubrik, in der ich zwischen 2000 und 2015 Anliegen von Leserinnen und Lesern behandelt habe, sind die Antworten nach «Tagesanzeiger»-Ausgaben archiviert. Pro Ausgabe sind meist mehr als eine Frage enthalten; zwei bis fünf, würde ich schätzen.
Die archivierte HTML-Datei umfasst alle Fragen aus einer Ausgabe. In der Datenbank sind aber alle Fragen einzeln erfasst – logischerweise, weil sich nur so die Beiträge vernünftig suchen und sortieren lassen. Das gleiche Problem hatte in vielen anderen Fällen auch: bei meinen Tipps für die Fachzeitschrift «Publisher» (zu den Adobe-Programmen und zu den Gestaltungs-Tipps im Web), zu Buch- und Software-Hinweisen und vielem mehr.
Wie man sich doch irren kann
Für eine automatisierte Übernahme musste ich die HTML-Dateien entsprechend aufsplitten und die «Fragmente» dem passenden Eintrag aus der Datenbank zuordnen. Man denkt sich, das sei ein Klacks, weil schliesslich jeder Beitrag ein Erscheinungsdatum und einen Titel hat. Und diese beiden Daten eigentlich ausreichend sein müssten, eine Übereinstimmung herzustellen.
Das war ein Trugschluss. Das Grundproblem besteht darin, dass eine über zwei Jahrzehnte angehäufte Sammlung von Dateien viel zu wenig konsistent ist, dass man sie automatisiert in den Griff bekommen würde. Nur einige Beispiele, was für Fussangeln ich begegnet bin:
Wie identifiziert man einen Titel?
Damit die Zuordnung funktioniert, muss in der HTML-Datei der Titel eines Artikels bzw. Teilbeitrags identifiziert werden: Dann kann man die Datei aufsplitten, den Titel in den Dateinamen des Fragments schreiben und das über ein Script dem entsprechenden WordPress-Post zuordnen.
Leider gibt es unzählige Möglichkeiten, wie man in HTML einen Titel formatieren kann. Ideal wäre natürlich, wenn ein grosser Titel mit h1-Tag, ein etwas weniger grosser mit h2-Tag ausgezeichnet wäre – und so weiter.
Dem ist aber nicht so. Meine HTML-Dateien stammen aus verschiedenen Content-Management-Systemen und aus der Schweizer Mediendatenbank SMD, die – wie hier ausgeführt – eine eigenwillige Vorstellung von der Verwendung der HTML-Auszeichnungssprache hat.
Viele der Dateien aus der Anfangszeit des «Publisher» waren noch handgeklöppelt, und nicht alle Leute, die an der Website gearbeitet haben, waren Meister ihres Fachs.
Will sagen: Meistens sind die Titel über irgendwelche CSS-Klassen formatiert, die mal .title, mal .HT, mal .ht, und zwischendurch auch .uber3 heissen. Bei aufgesplitteten HTML-Dateien kann es passieren, dass die erste Überschrift im Beitrag eigentlich ein Zwischentitel ist und mit .zt o.ä. ausgezeichnet ist. Und gelegentlich hatten Leute auch die hirnrissige Idee, Titel über span-Elemente zuzuweisen.
Als ob das nicht unerfreulich genug wäre, gibt es auch die Erfindung der Spitzmarke, die eine Rubrik oder ein Thema angibt. Die wird in der Datenbank manchmal dem Titelfeld zugeschlagen, manchmal nicht. Ein Titel kann in WordPress daher entweder «Photoshop – Tipps für Ebenen» oder auch nur «Tipps für Ebenen» lauten.
In einigen Dutzend Dateien habe ich in den Titeln noch weitere Tags gefunden. In einigen waren dort Bilder eingebettet. Das kann man natürlich tun – man muss aber nicht.
HTML-Ballast
Die archivierten HTML-Dateien enthalten leider nicht nur den Text, sondern in vielen Fällen auch Navigation und anderer Ballast. Solcherlei Zeugs will ich natürlich nicht in WordPress drin haben, sondern nur den eigentlichen Artikel.
Einige der Dateien aus den Anfängen des Webs sind mit Font-Tags durchsetzt oder über Tabellen aufgebaut. Das zu bereinigen, ist eine nervtötende Angelegenheit.
Falls ihr jemals vor einer ähnlichen Herausforderung steht: Notepad++ (Das Textmonster) ist für solche Zwecke ein grossartiges Hilfsmittel. Es hat eine blitzschnelle Suche mit regulären Ausdrücken, die man über eine grosse Zahl von Dateien laufen lassen kann und mit der man Stück für Stück alles herauslöscht, was man nicht in seinen Dateien benötigt. Ein Tipp: Die Dateien häufig sichern, denn wenn man einen Fehler macht, hat man nicht nur den Ballast, sondern auch den Nutzinhalt entfernt.
Codepage-Querelen
Was viele von uns verdrängt haben, ist die Tatsache, dass es Unicode nicht seit ewig gibt. Einige der HTML-Dateien geben an, welche Zeichensatztabelle für ihre Erstellung verwendet wurde. Wenn man diese Angabe weglässt, werden Umlaute und Sonderzeichen falsch dargestellt.
Da meine HTML-Seiten bis ins Jahr 1999 zurückreichen, habe ich eine wilde Mischung von Codierungen vorgefunden. Dieses Problem kannte ich bereits (Immer Ärger mit dem BOM). Neu war mir allerdings, dass ein Webserver unter Umständen eigenmächtig irgendwelche Codierungs-Angaben in HTML-Dateien hineinschreibt, wenn keine vorhanden sind.
Damit hat er mich fast zum Weinen gebracht. Ich hatte nämlich die Idee, alle Dateien nach Unicode zu konvertieren. Da die aufgesplitteten HTML-Dateien aber keinen Header mehr hatten, hat der Webserver (oder vielleicht auch die FTP-Gegenstelle) einen leider völlig unzutreffenden Header ergänzt, was dazu führte, dass sämtliche Umlaute kaputtgegangen sind. Um das zu vermeiden, habe ich den aufgesplitteten Dateien nicht die Endung .html hinzugefügt, sondern .raw.
Fazit: Es ging nicht ohne Handarbeit
Das alles hat mich zur Einsicht gebracht, dass das Projekt «Reclaim the formats» bedauerlicherweise nicht ohne Handarbeit zu bewältigen ist. Es braucht die manuelle Kontrolle, dass ein Plain-Text-Eintrag durch das richtige HTML-Fragment ersetzt wird. Und dort, wo die Zuordnung nicht automatisch erfolgen konnte, musste ich von Hand den passenden Inhalt einkopieren.
Hätte ich das schon von Anfang an gewusst, hätte ich vielleicht die Finger davon gelassen. Doch da die Erkenntnis erst während des Projekts gereift ist, habe ich es dann doch durchgezogen. Über den Daumen gepeilt bei zwei Dritteln der Beiträge hat die Zuordnung geklappt – und dort war die Übernahme erstaunlich unproblematisch. Doch bei einem Drittel musste ich selbst Hand anlegen, was bei 8100 Einträgen doch einige Stunden Arbeit bedeutete.
Beitragsbild: Wie aus einem Haufen von Dateien und Datenbankeinträgen ein stimmiges Gesamtbild wird (Hans-Peter Gauster, Unsplash-Lizenz).