
Neulich habe ich mit den Alerts einen Google-Dienst vorgestellt, der uralt, aber nichtsdestoweniger ausgesprochen praktisch ist. Da passt es doch, wenn ich mich einer weiteren Funktion zuwende, die ebenso die Eigenschaften aufweist, schon seit langem zu existieren und im Alltag immer mal wieder gute Dienste zu leisten.
Das ist der Google Cache. Dort werden Webseiten zwischengespeichert und stehen zum Abruf, wenn das Original nicht zugänglich sein sollte. Man kann sich somit Informationen holen, die entweder temporär oder dauerhaft aus dem Web verschwunden sind.
Einen solchen Fall hatte ich neulich: Dazumal war der Jooki meiner Tochter (Eine Lautsprecherbox fürs Kinderzimmer) beim Abschalten hängen geblieben. Google verweist zu diesem Problem auf den Supportbeitrag Turning off a stuck Jooki, doch beim Klick auf den Link tauchte keine Website auf. Vermutlich war der Server unpässlich.
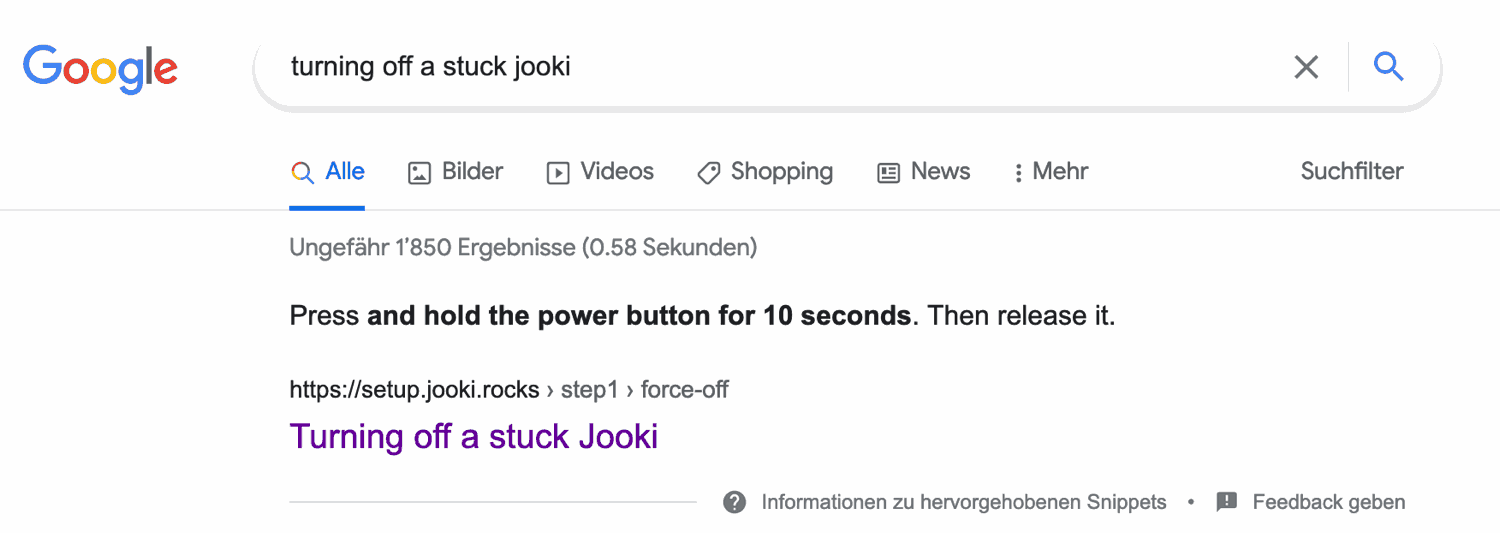
Statt zu warten¹, habe ich die Seite aus dem Cache von Google geholt und dort die benötigte Information bekommen.
Via Google-Suchresultate zu der Webseiten-Kopie
Um auf die gecachte (zwischengespeicherte) Version einer Webseite zuzugreifen, klickt man in der Google-Suche auf das nach unten zeigende Dreieck, das hinter der Adressangabe im Eintrag in der Liste mit den Suchresultaten erscheint. Das bringt ein Menü mit dem Befehl Im Cache zum Vorschein.
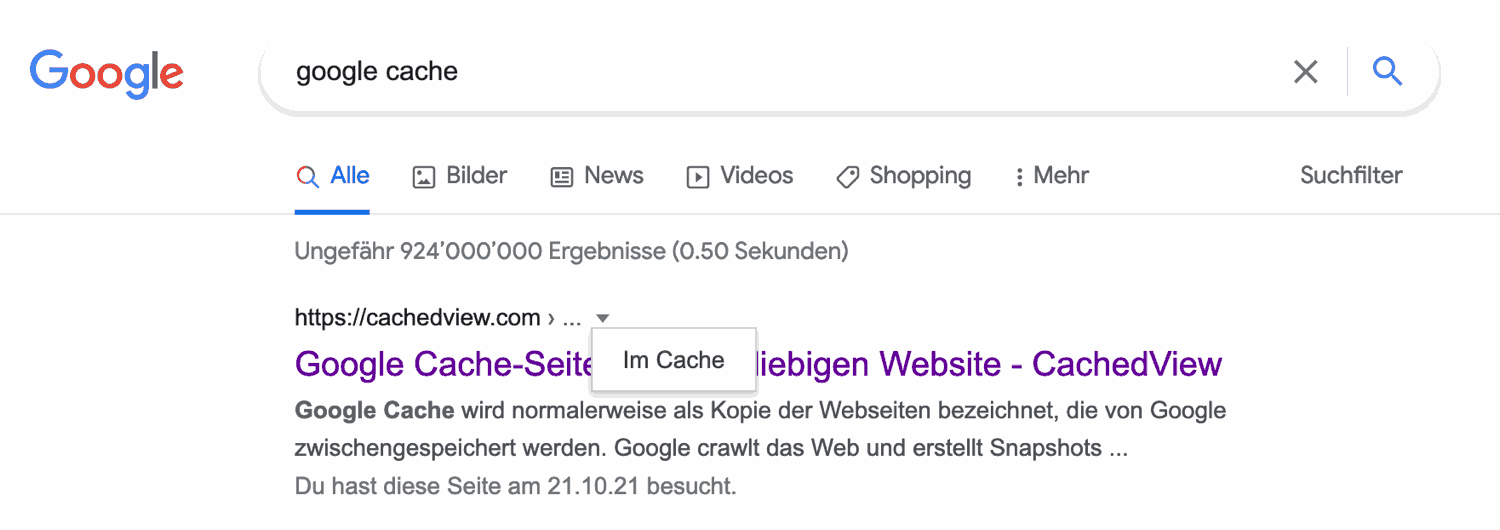
Allerdings gibt es das Menü nicht immer – gerade beim fraglichen Eintrag zum erwähnten Jooki-Supportbeitrag fehlt es. Doch auch für solche Fälle gibt es Hilfe:
In manchen Browsern braucht man im Adressfeld der URL nur den Eintrag cache: voranzustellen (anstelle des http/https), um den Inhalt nicht direkt, sondern aus Googles Zwischenspeicher abzurufen. Das funktioniert in Firefox und in Google Chrome. In Safari hat es bei meinem Test nicht geklappt.
Web-Archives-Browser-Erweiterung
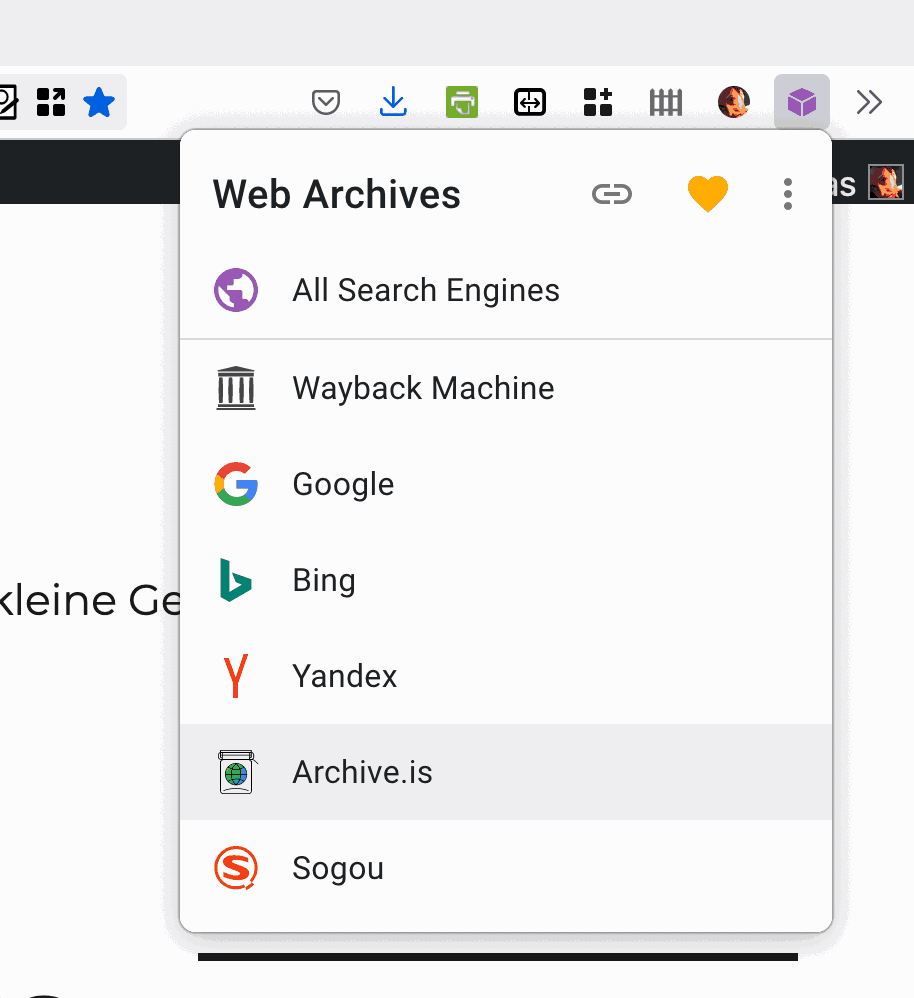
Für Firefox und Chrome gibt es Erweiterungen, die den Zugriff auf den Cache erleichtern. Die spannendste scheint mir Web Archives zu sein (Firefox/Chrome): Mit ihr ruft man die zwischengespeicherte Variante einer Website über den Knopf in der Menüleiste ab.
Man das nicht nur via Google tun, sondern auch die Caches der anderen Suchmaschinen nutzen, namentlich Bing, yandex.com, Wayback Machine und Archive.is (mehr zu den beiden weiter unten) und sogou.com.
Eine Alternative für Chrome dazu wäre Web Cache Viewer bzw. Google Cache für Firefox.
Cachedview.com
Für Safari und andere Browser, die den Trick nicht unterstützten, gibt es eine zweite Möglichkeit: Die Site cachedview.com erlaubt es, den Google Cache zu durchsuchen: Man kopiert die Internet-Adresse (URL) ins Eingabefeld und erhält das Resultat. Zumindest, sofern eine Zwischenspeicherung existiert.

Wayback Machine
Es gibt nebst Google noch weitere Möglichkeiten, auf Kopien von Websites zuzugreifen. Da ist die Wayback Machine von archive.org: Sie eignet sich weniger für aktuelle Recherchen, weil sie teils lückenhaft und oft recht langsam ist.
Aber da sie Websites versioniert und zum Teil auch weit zurückreichende Bestandsaufnahmen bereithält, ist sie das ideale Instrument für «historische» Recherchen: Man findet auch Inhalte, die auf der Originalsite schon längst verschwunden sind.
Trotzdem lautet meine Empfehlung, sich nicht darauf zu verlassen: Wenn man sicher sein will, Informationen aus dem Web jederzeit zur Verfügung zu haben, muss man sie selbst offline archivieren. Tipps dazu gebe ich im Beitrag Selbst speichern, was man wirklich braucht.
Archive.is
Zur Archivierung bietet sich die Website archive.is (archive.today) an: Sie erstellt Kopien von Websites, die online verfügbar bleibt, selbst wenn das Original verschwunden ist. Man kann selbst die Archivierung veranlassen, aber auch im Archiv suchen. Im Vergleich zu Google scheint mir dieser Zwischenspeicher weniger umfangreich.
Ein paar Fragen bleiben. Erstens: Weiss man, wie umfangreich dieser Google Cache ist? Dazu habe ich auf die Schnelle keine schlüssigen Informationen gefunden.
Ist das eigentlich legal?
Zweitens: Ist es eigentlich legal, Websites zwischenzuspeichern bzw. mit welcher Rechtsgrundlage machen die Suchmaschinen das?
Darüber hat ein Gericht befunden, wie man hier nachlesen kann:
Demnach hat ein Autor und Anwalt Blake Field ein Verfahren wegen Urheberrechtsverletzung angestrengt, weil Google dessen Website zwischengespeichert hat. Ein Richter namens Jones hat die Klage mit einer folgender Begründung abgewiesen:
Wenn ein Nutzer eine im Google-Cache enthaltene Webseite anfordert, indem er auf einen «Cached»-Link klickt, ist es der Nutzer und nicht Google, der eine Kopie der im Cache gespeicherten Webseite erstellt und herunterlädt. Google ist bei diesem Vorgang passiv. Ohne die Anfrage des Nutzers würde die Kopie nicht erstellt und an den Nutzer gesendet werden, und die angebliche Rechtsverletzung, um die es in diesem Fall geht, würde nicht stattfinden. Das automatisierte, nicht-willkürliche Verhalten von Google als Reaktion auf die Anfrage eines Nutzers stellt keine unmittelbare Verletzung im Sinne des Urheberrechtsgesetzes dar.»
Aus meiner Sicht ist das kreuzfalsch; denn natürlich existiert die zwischengespeicherte Variante schon, bevor der Nutzer auf den «Cached»-Link klickt – denn der Nutzer tut das in aller Regel genau deswegen, weil das Original im fraglichen Zeitpunkt eben nicht verfügbar ist. Aber ich werde mal nicht allzu laut auf den Denkfehler von Richter Jones hinweisen, weil ich den Google Cache auch weiterhin gerne nutzen möchte.
Fussnoten
1) Hätte man genau hingeschaut, dann hätte man entdeckt, dass Google schon in den Suchresultaten die entscheidende Information hervorgehoben hat: Press and hold the power button for 10 seconds. Eben – lesen müsste man können. ↩
Beitragsbild: Wie tief muss man graben, damit die alten Websites zum Vorschein kommen? (Lukas, Pexels-Lizenz)