
Google News ist seit 2002 am Start: Unter news.google.com werden die Schlagzeilen vieler Newssites aggregiert. Wer keine bevorzugte Nachrichtenquelle hat, kann sich dort durch die Nachrichtenlage klicken.
Wie es Googles Art ist, bekommen nicht alle das gleiche Angebot, sondern eine personalisierte Variante davon. Ich bin kein Fan Google News, sondern halte das für eine erstaunlich schlechte Google-App. Und ich halte an der Meinung fest, dass man sich seine News nicht von Google (oder sonst wem) auswählen lassen sollte, sondern sie selbst kuratieren muss. Der Tipp dazu ist RSS und eine vielversprechende Möglichkeit, den zu nutzen, ist die Feedbro-Erweiterung für Firefox.
Trotzdem ergibt sich hier die Gelegenheit, auf Google News zurückzukommen. Mir ist neulich per Zufall aufgefallen, dass es dort nicht nur neue, sondern auch alte News gibt. Unter news.google.com/newspapers findet sich ein Archiv von eingescannten Zeitungen, das an Google Books erinnert – das wiederum ein Google-Dienst, den ich sehr gern nutze.
Soweit ich sagen kann, sind Zeitungen aus Nordamerika archiviert. Auf mich, der ich kein Experte für die US-amerikanische Zeitungslandschaft bin, macht die Auswahl einen willkürlichen bis chaotischen Eindruck: Aber das kann auch daran liegen, dass Googles Präsentation wirklich schlecht ist: Die Zeitungstitel werden alphabetisch aufgelistet und zwar auf eine Art und Weise, die spätestens 2005 nicht mehr hip war. Es gibt keine Möglichkeit, die Zeitungen geografisch, nach Zeitabschnitten oder sonstwie einzugrenzen und es stehen Titel, die nur ein paar wenige Male erschienen sind, gleichwertig neben Publikationen, von denen es Zehntausende Ausgaben gibt.
Einfacher hätte es sich Google nicht mehr machen können
Noch miserabler ist die Suchfunktion: Und das will wirklich etwas heissen, zumal dieses Zeitungsarchiv nicht von einem technophoben Bibliothekarsverband ins Netz gestellt wurde, sondern vom grössten und wichtigsten Suchmaschinenkonzern der Welt. Wenn man einen Suchbegriff eingibt – ich habe es probehalber mit «kennedy assassination» probiert – dann führt das zu einer normalen Google-Suche, die lediglich mit dem Parameter site:news.google.com/newspapers ergänzt wird.
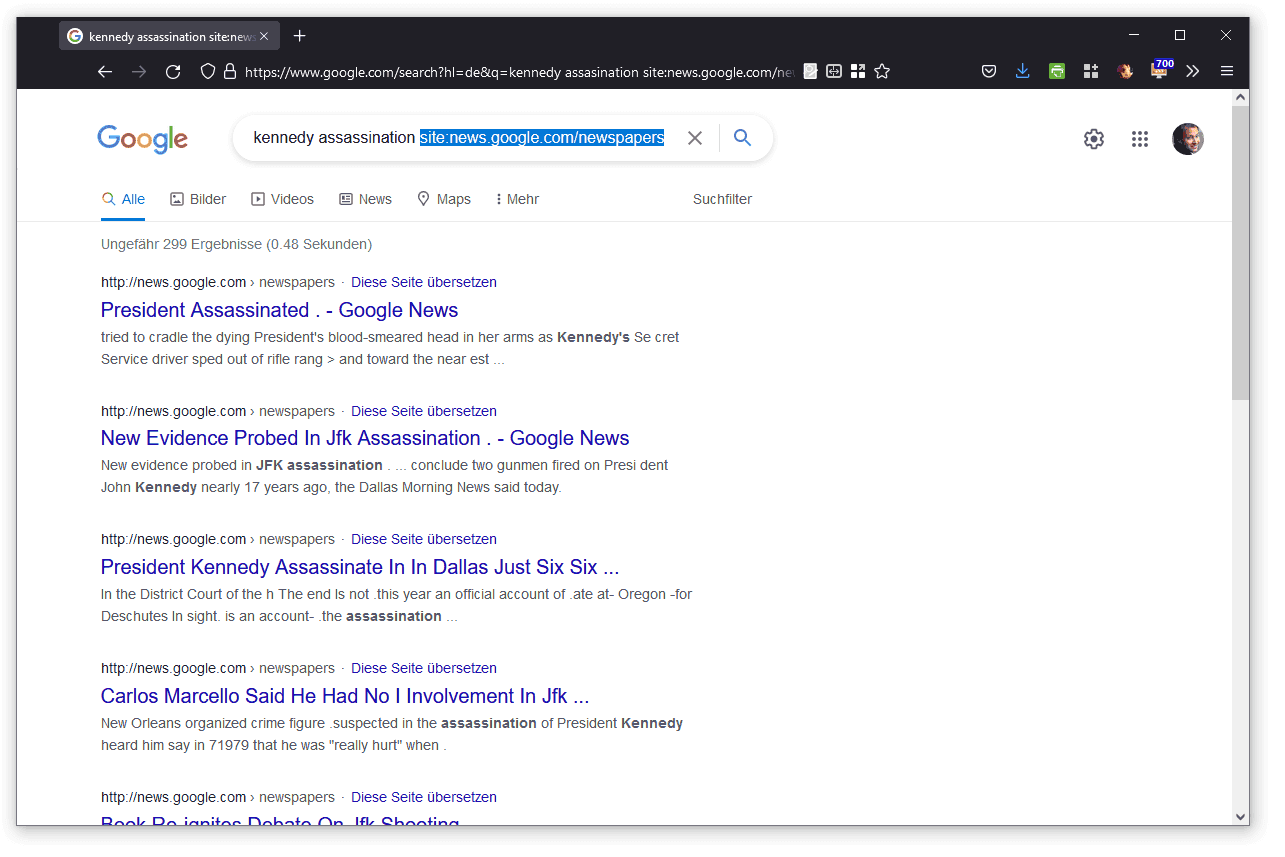
In der Liste der Resultate sieht man weder den Namen der Zeitung, auf die ein Treffer verweist, noch das Datum der Publikation. Wenn man das in Erfahrung bringen will, muss man den Treffer anklicken – was bei populären Themen völlig unzumutbar ist.
Was die Lokalpresse damals schrieb
Eine weitere Schwachstelle ist die Sortierung. Wenn ich zum Stichwort «kennedy assassination» den ersten Treffer anklicke, lande ich bei «The Lewiston Daily Sun», die in der Sonntagsausgabe vom 23. November 1963 über die Ermordung des Präsidenten berichtet.

Wikipedia verrät mir, dass The Lewiston Daily Sun eine Zeitung ist, die von 1893 bis 1989 in Lewiston im US-Bundesstaat Maine erschienen ist. Ich will nun keinem der etwa 40’000 Einwohner aus diesem Ort zu nahe treten, aber es gibt keinen offensichtlichen Grund, weswegen ihre Lokalzeitung die Trefferliste anführen sollte. Die Auflage 1963 der Zeitung wird nicht angegeben, aber anfangs des Jahrhunderts betrug sie um die 8000 Exemplare – daher handelt es sich vermutlich nicht um eine der massgeblichen Publikationen aus den USA, die man als Erstes würde berücksichtigen wollen.
Treffer zwei: «The Telegraph» vom 2. Oktober 1980 mit einem Artikel, in dem es um neue Beweise geht. Treffer drei: «The Bulletin» vom 22. Mai 1964 mit einem Rückblick auf die sechs Monate nach der Ermordung von John F. Kennedy.
Wo ist das «The Wall Street Journal»? Wo die «New York Times»?
Ich will nun nicht wie ein undankbarer Honk erscheinen, zumal Google dieses Angebot völlig kostenlos macht und es mir erlaubt, Zeitungen zu durchforsten, ohne dass ich meinen Hintern in den muffigen Leseraum einer Bibliothek bewegen oder mich durch Berge von Mikrofilmen kämpfen müsste. Aber trotzdem: Geht es noch, Google? Natürlich will ich zu diesem Thema den Artikel aus «The Wall Street Journal», aus «The New York Times», aus der «Los Angeles Times» oder meinetwegen «New York Post», «The Washington Post», «Star Tribune», «Chicago Tribune» oder dem «Houston Chronicle» lesen.
Leider ist keine dieser Zeitungen archiviert. Ich gehe davon aus, dass die ihre Archive selbst verwalten und verwerten und Google nicht erlauben, ihre alten Zeitungen ins Netz zu stellen – wobei man sich beispielsweise im Fall des The Wall Street Journals auf die Position stellen könnte, dass zumindest die alten Ausgaben unbedingt kostenlos ins Netz gehören: Es gibt diese Zeitung seit 130 Jahren, sodass man davon ausgehen kann, dass zumindest für die ersten dreissig, vierzig Jahrgänge das Urheberrecht auf alle Fälle abgelaufen ist.
Fazit: Natürlich ist so ein Archiv natürlich besser als gar nichts. Aber es weckt die Lust auf mehr. Warum verfolgt Google das Ziel, ein digitales Zeitungsarchiv aufzubauen, nicht ernsthaft? Allein das Design macht den Eindruck, als ob jemand 2002 hier einen ersten Versuch unternommen hätte, danach das Interesse an diesem Projekt aber komplett erlahmt ist. Das ist schade – aber es passt zu Google als Konzern mit einer extrem kurzen Aufmerksamkeitsspanne, der Dinge sofort wieder bleiben lässt, wenn sie keine instant gratification vermitteln.
Beitragsbild: «The New York Times» gibt es bei Google nicht – und den Kaffee übrigens auch nicht (Cottonbro, Pexels-Lizenz).
Für australische Zeitungen ist der dortige Bestand auf “trove” besser aufgearbeitet. Google hat diese Zeitungen digitalisiert weil zahlreiche amerikanische Bibliotheken aus Platzgründen allenfalls Mikrofilme lagern wollten nd massenhaft wegwarfen. Das war etwa zu der Zeit als man auch etliche Großbibliotheken dazu brachte ihre Altbestände scannen zu lassen. Die pariser Bibliotheque Nationale hat den Herrschaften schleunigst die Tür gezeigt und gallica aufgebaut. Die bayerische Staatsbibliothek München war, wie etliche amerikanische Bibliotheken, dumm genug auf den Deal einzugehen,statt mehr Massenentsäuerung zu machen. Die so erstellten miserablen b/w-Scans sind nun die Basis von google books, die teilweise kostenpflichtig sind. (Microsoft fuhr zu der Zeit ein ähnliches Programm mit deutlich besseren color-Scans). Google hatte zu der Zeit Ärger mit einem Japaner, der urheberrechtlich geschützte Bücher von sich dort nicht sehen wollte. Google plante das Wissen der Welt auf ihre Server zu bekommen. Scheint den Turbokapitalisten irgendwann nicht mehr wichtig gewesen zu sein. Vieles älteres findet sich dann auch auf archive.org von google hochgeladen.