
In meiner losen Serie zu alten, seltsamen und wenig bekannten Google-Diensten ging es neulich um Google News, bzw. das zu Google-News gehörende digitale Zeitungsarchiv mit Suchmaschine für alte News. Das ist theoretisch eine tolle Sache, praktisch aber annähernd unbrauchbar – leider. Entsprechend war der Beitrag zu meinem Bedauern nur von bescheidener Nützlichkeit.
Das ist mit dem heutigen Tipp diametral anders: Zwar kennen diese spezielle Suchmaschine ebenfalls längst nicht alle Leute, die alles nutzen, was Google ansonsten zu bieten hat. Aber sie leistet hervorragende Dienste, zumindest für Recherchen, die sich mit den Trends der Vergangenheit beschäftigen. Es handelt sich um den Google Ngram Viewer, zu finden unter books.google.com/ngrams.
Die Suchmaschine verwendet die Daten von Google Books, der grossen Sammlung an digitalisierten Büchern, die der Konzern seit 2004 betreibt. Zum 15. Jubiläum 2019 konnte man im firmeneigenen Blog lesen, wie viele Bücher dort vorhanden sind: Es seien vierzig Millionen Bücher in vierhundert Sprachen, heisst es. Ich nutze Google Books routinemässig für Recherchen und habe seinerzeit auch eine etwas fragwürdige Erfindung namens Books Downloader vorgestellt, die genau das tut, was man dem Namen nach von ihr erwarten würde.
Mit Google Books recherchieren
Google Books ist ein wertvolles Rechercheinstrument: Man findet Bücher, die sich mit einem bestimmten Thema beschäftigen, ohne dass man sich durch die Zettelkästen unzähliger Bibliotheken kämpfen müsste. Vor allem findet man auch jene Bücher, die einen Gegenstand nur kurz streifen oder nebenbei erwähnen. Zwar erspart es einem Google Books oft nicht, ein Buch zu kaufen oder auszuleihen, weil man nur Textausschnitte zu sehen bekommt – aber immerhin kann man meist hervorragend abschätzen, ob sich der Aufwand lohnt oder nicht. Und manchmal reicht auch schon die Vorschau.
Und eben: Wenn man so viele Bücher auf einem digitalen Haufen hat, kann man noch mehr mit ihnen anstellen – nämlich Trends herauslesen: Via Ngram Viewer findet man heraus, wann ein Begriff zum ersten Mal in einem Buch erwähnt wurde und wie sich die Zahl der Nennungen über die Zeit entwickelt hat. Peter Schneider hat das neulich schön für den Begriff der Dystopie vorexerziert. Er ist nämlich keine neumodische Erscheinung, wie jemand unterstellt hat, sondern ein altgedientes Konzept, das über die digitalisierte Büchersammlung bis ins Jahr 1880 zurückverfolgt werden kann.
Der Haupteinwand gegen diese Rechercheform liegt auf der Hand: Google hat längst nicht alle Bücher digitalisiert, ergo kann es gut sein, dass der Ausschnitt, den man via Ngram Viewer abfragt, ein verzerrtes Bild der Realität liefert.
Wie viele Bücher gibt es denn überhaupt?
An dieser Stelle drängt sich ein kleiner Exkurs auf, nämlich die Frage, wie viele Bücher denn ungefähr existieren – so kann man abschätzen, wie gross der Anteil ist, der bei der Nutzung des Ngram-Viewers im Dunkeln bleibt. «The Atlantic» gibt uns die Antwort, es seien exakt 129’864’880 Stück. Diese Zahl stammt wiederum von Google und sollte in diesem Kontext darum wahrscheinlich mit einem Körnchen Salz genossen werden. Trotzdem kommen wir zum Schluss, dass Google etwa einen Drittel digitalisiert hat. Mein Bauchgefühl besagt allerdings, dass das viel zu hoch gegriffen ist – da muss es noch viel mehr Wissen geben, das sich der Digitalisierung entzogen hat.
Ein zweites Problem besteht darin, dass nicht alle Themen, die die Menschen beschäftigt haben, in Büchern ihren Niederschlag gefunden haben. Die Zensur gab es in früheren Zeiten, sodass heikle Bereiche ausgeklammert oder durch die Blume formuliert worden sind – und wenn ein Wort nicht dasteht, sondern umschrieben worden ist, dann erscheint es im Ngram Viewer nicht.
Abgesehen davon, dass es auch vielerlei andere Probleme gibt: Die Bücher sind digitalisiert worden. Doch die Texterkennung (OCR) ist alles andere als perfekt. Wenn ein Wort falsch erkannt wurde, dann taucht es nicht auf. Auch unterschiedliche Schreibweisen wären zu beachten – und welche Probleme mehrdeutige Begriffe machen, liegt auf der Hand.
Mit Verzerrungen muss gerechnet werden
Der Wikipedia-Beitrag liefert noch weitere Kritikpunkte:
Der Datensatz wird kritisiert, weil er auf einer ungenauen OCR beruht, ein Übermass an wissenschaftlicher Literatur enthält und eine grosse Anzahl falsch datierter und kategorisierter Texte umfasst. Aufgrund dieser Fehler und weil er nicht auf Verzerrungen kontrolliert wird (z. B. die zunehmende Menge an wissenschaftlicher Literatur, die dazu führt, dass andere Begriffe scheinbar an Popularität verlieren), ist es riskant, diesen Korpus zur Untersuchung von Sprache oder zur Überprüfung von Theorien zu verwenden. Da der Datensatz keine Metadaten enthält, spiegelt er möglicherweise keinen allgemeinen sprachlichen oder kulturellen Wandel wider und kann einen solchen Effekt nur andeuten.
Alles berechtigte Kritikpunkte, von denen einzelne auch auf Google Trends zutreffen (siehe hier).
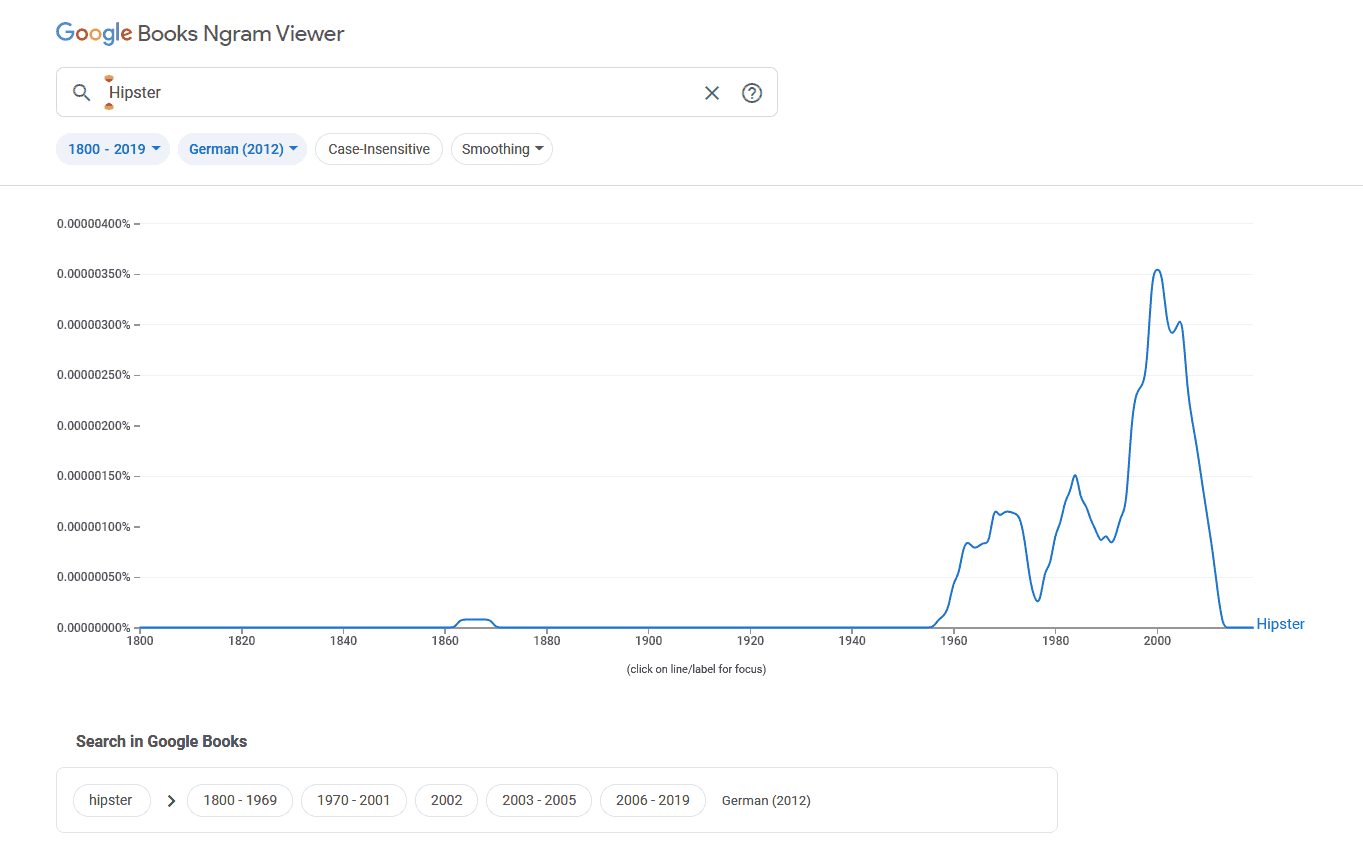
Trotzdem: Wenn man den Ngram Viewer mit kritischer Distanz nutzt, dann ist er ein spannendes und erhellendes Rechercheinstrument. Ich habe zum Beispiel gelernt, dass entgegen meiner Meinung das Wort «Hipster» längst keine Erscheinung der letzten paar Jahre ist. Es tauchte schon 1863 bis 1868 in deutschsprachigen Büchern auf und dann wieder ab 1957.
Zugegeben – das hätte mir auch Wikipedia verraten. Aber so habe ich die Entdeckung selbst gemacht, und das war definitiv spassiger
Beitragsbild: Er ist auch nicht mehr der jüngste (Iiii Iiii, Pexels-Lizenz).