
Es gebe eine «Text-zu-Bild-Revolution», kann man in den Medien lesen. Es gibt diese künstlichen Intelligenzen, die aus kurzen Textvorgaben Bilder generieren – und damit verblüffen, irritieren und Illustratoren in Angst und Schrecken versetzen.
Für die Tamedia habe ich vor einiger Zeit Dall-e mini vorgestellt; ein solches System, das inzwischen Craiyon heisst. Ich wollte wissen, wie es sich im Vergleich mit anderen Systemen seiner Art schlägt – denn davon sind in letzter Zeit einige aufgetaucht. In meinem Vergleich kommen nebst Craiyon auch Artbreeder und Starryai zum Zug. Und natürlich Stable Diffusion¹. Nachtrag: Und nachträglich habe ich die Resultate von Dall·e 2 ergänzt, die ich von Manuel erhalten habe. Danke dafür!

Dieses Stable Diffusion ist auch der Grund, weswegen sich ein solcher Vergleich gerade jetzt aufdrängt: Es hat die Karten neu gemischt, behaupten die Medien.
Diese Software unterscheidet sich von den Konkurrenten, weil sie eine freie Lizenz hat und Open-Source ist. Man kann sie herunterladen und selbst betreiben – und damit auch einen Blick hinter die Kulissen riskieren. Ich werde das bei Gelegenheit selbst tun – aber die Bilder, die hier zu sehen sind, hat eine Installation im Netz gerechnet.
Und der KI-Oskar geht an …!
Also, jetzt wollt ihr natürlich wissen, was bei meinem kleinen Vergleich herausgekommen ist. Ich habe zwei abstrakte Vorgaben gemacht. Die Systeme sollten mir erstens «die schönste Frau der Erde mit Fuchsohren und einem Hasenschwänzchen» generieren, zweitens «das Matterhorn aus Schokolade, mit Schlagrahm obendrauf».
The most beautiful girl on earth with fox ears and a rabbit tail
Diese Aufgabe ist für jeden halbwegs begabten Manga-Zeichner ein Klacks: Eine wunderschöne Frau, die die Ohren eines Fuchses und den Schwanz eines Hasen besitzt. Wie würde die wohl aussehen?
Das sind die Resultate:

Und ja, Stable Diffusion gewinnt. (Und wie man sieht, habe ich hier bei der Formulierung der Frage einen Fuchsschwanz und Hasenohren verlangt, was auch mehr Sinn ergibt).
Das Bild ist in sich stimmig – nur die Augen sehen ein bisschen seltsam aus. Aber der Uncanny Valley-Effekt – also der Umstand, dass ein Bild lebensecht wirken soll, aber uns mit kleinen Fehlern irritiert – ist gering.
Trotzdem: Die Aufgabe ist verfehlt, weil der Schwanz natürlich hinten an der Frau zu finden sein müsste. Ein Fuchsschwanzwedel erfüllt den Zweck nicht.
Aber hübsch: Das Oberteil wirkt ebenfalls pelzig! Das gibt Extrapunkte.
Von den Konkurrenten kann nur Craiyon einigermassen überzeugen. Aber die Gesichter wirken gruselig – wie ein blutiger Amateur, der sich als Picasso versucht.
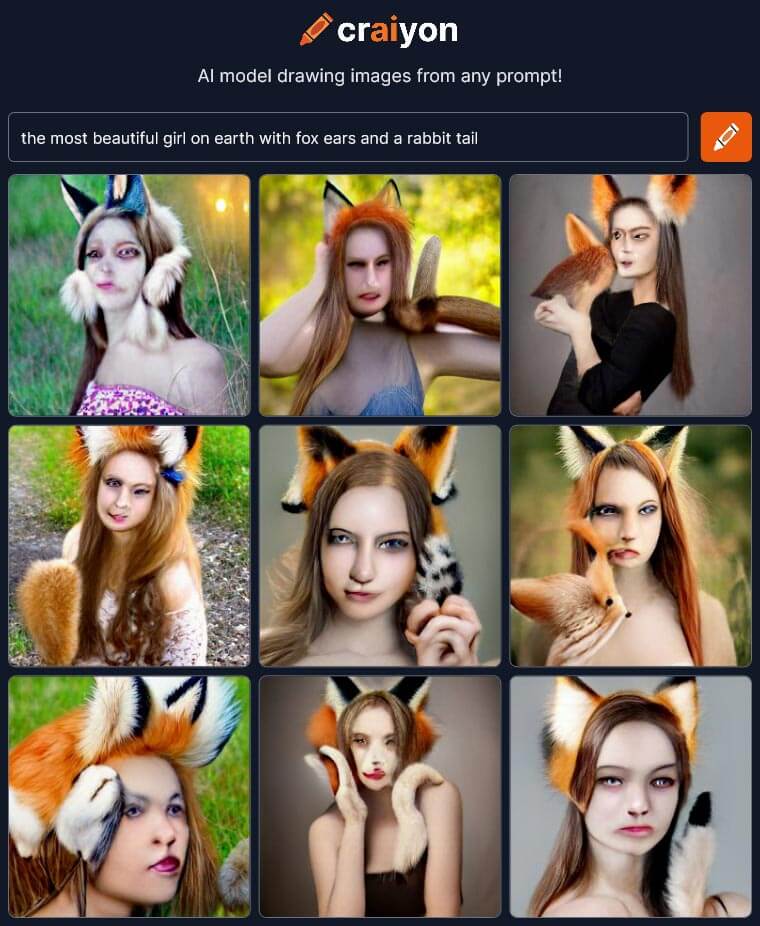
Über die beiden anderen Kandidaten müssen wir nicht diskutieren. Diese Bilder sind unbrauchbar und durchgefallen.


Nachtrag: Und hier das Resultat von Dall·e 2, das ich nach Veröffentlichung des Beitrags – und damit nach Erscheinen der offiziellen Rangliste von Manuel bekommen habe.

Ich würde sagen: Keines der Bilder erfüllt die Aufgabe perfekt. Aber die Stilvarianten sind Ehrfurcht gebietend. An dieser Stelle beginnt man zu ahnen, weshalb sich gestandene Illustratoren von diesen Programmen bedroht fühlen. Denn mit etwas Politur und Nachbearbeitung könnten diese Werke in Büchern, Magazinen oder auch in Blogs wie diesem hier Verwendung finden.
The matterhorn made of chocolate with cream on top
Auch die zweite Aufgabe ist für einen echten Kunstmaler keine Herausforderung. Wie würde das Matterhorn aussehen, wenn es aus Schokolade und von Schlagrahm gekrönt wäre?
Der Sieger ist eindeutig Craiyon: Die Umsetzung ist künstlerisch zwar stark verbesserungsfähig. Aber die Aufgabe wurde verstanden: Es gibt ein Schokolade-Dessert mit einem Sahnehäubchen zu sehen, das die Form eines Bergs hat.
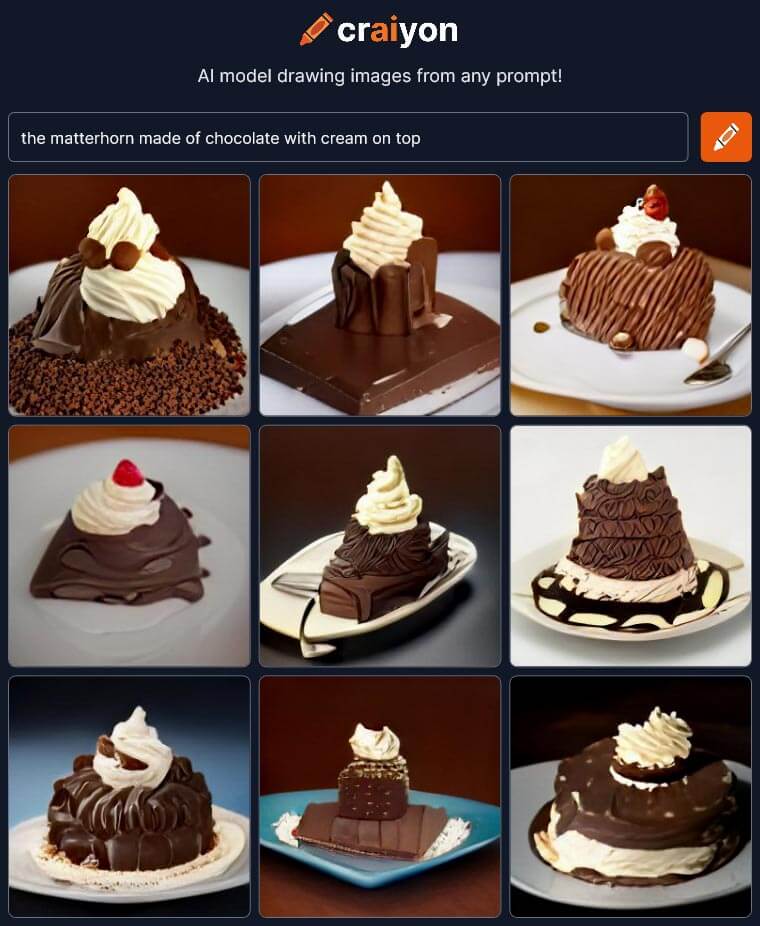
Die nachfolgenden Plätze sind knifflig. Ich vergebe den Platz zwei ex-aequo an Stable Diffusion und an Artbreeder: Bei ersterem ist das Matterhorn erkennbar, aber da die Schokolade daneben liegt, ist entspricht das nicht der Aufgabe. Artbreeder hat ein Schokotörtchen hinbekommen, das aber wirklich nicht nach Matterhorn ausschaut.


Starryai ist auch bei dieser Aufgabe durchgefallen. Obwohl die schmierige Substanz auf dem Tisch Schokolade sein könnte, fehlt diesem Bild jegliche kulinarische Ästhetik. Und die Berge scheinen aus Dollarscheinen zu bestehen.

Nachtrag: Und so hat Dall·e 2 die Aufgabe gelöst:

Auch hier bleibt die Erkenntnis, dass ein menschlicher Künstler das Matterhorn besser herausgearbeitet hätte. Doch der Fotorealismus dieser Werke ist frappant!
Geht diese Entwicklung in diesem Tempo weiter?
Gibt es an dieser Stelle ein Fazit, das wir ziehen könnten? Ist das eine Revolution, wie eingangs postuliert? Verändert das unsere Sichtweise auf die Funktionsweise der Computer und den Wert menschlicher Kreativität?
Für diese Fragen muss ich etwas ausholen.
An künstliche Intelligenzen wie Siri haben wir uns gewöhnt: Es ist nicht mehr aussergewöhnlich, dass wir mit digitalen Entitäten interagieren, ihnen Aufträge erteilen und Aufgaben an sie delegieren.
Wir überantworten diesen KIs die Gestaltung unserer musikalischen Berieselung via Spotify und lassen sie auf Netflix Filme für uns auswählen. Oder wir flirten mit ihnen und sehen, wohin das führt. Allerdings hält sich das Vertrauen bislang in engen Grenzen. Derzeit würde ich nicht in ein selbst lenkendes Auto einsteigen oder mich von einem KI-Doktor behandeln lassen. Zumindest nicht ohne ein menschliches Backup.
Doch diese künstlichen Intelligenzen entwickeln sich weiter: Immer wieder höre ich Leute von GPT-3 schwärmen. Das ist eine KI, die angeblich hervorragend Texte generieren können soll. Sie kann Bücher zusammenfassen, Gedichte fabrizieren oder Bücher verfassen, die dann sogar publiziert werden.
Sollte man es KI nennen? Oder doch besser ML?
Trotzdem kann man sich wunderbar streiten, ob die Systeme wirklich intelligent sind und ihren Namen verdienen – oder ob die Fortschritte nicht einfach damit zu erklären sind, dass ihnen mehr Rechenleistung zur Verfügung steht und sie auf riesige Mengen an Daten zugreifen können. Das erleichtert das Training und zeigt das Potenzial des maschinellen Lernens (ML).
Ich habe eine klare Meinung zu dieser Frage: Ich sehe nach wie vor nur Imitation und keine echte Kreativität. Daran ändert auch die Tatsache nichts, dass man inzwischen mit Bots spielen kann, die auf Zuruf hin Bilder erzeugen. Das nennt sich wie eingangs erwähnt «Text-zu-Bild» und erfordert es, dass die Maschinen zwei wirklich schwierige Aufgaben lösen: Erstens müssen sie die gestellte Aufgabe richtig «verstehen» oder zumindest korrekt interpretieren. Und zweitens sollte das Bild, das sie daraus erzeugen, «gut» aussehen und keine Fehler wie falsch platzierte Augen oder verformte menschliche Anatomien aufweisen.
Nach meinem kleinen Vergleichstest geht es euch wahrscheinlich wie mir: Diese digitalen «Kunstwerke» wecken Faszination und Grusel zugleich, wobei der Grusel überwiegt.
Rettet euch auf den nächsten Baum!
Mit anderen Worten: Wenn die KIs so autofahren, wie sie Bilder kreieren, dann kann ich nur vor einem Ausflug in einem selbst lenkenden Gefährt warnen. Nicht nur das: Ich würde auch empfehlen, schleunigst auf den nächsten Baum zu klettern, wenn sich ein solches KI-Fahrzeug nähert!
Aber wenn die Entwicklung so weitergeht, dürfen wir gespannt sein, wo wir in zwei oder fünf Jahren stehen. Das Rationalisierungspotenzial im Bereich der grafischen Gestaltung ist gerade bei Dall·e 2 unübersehbar!
Fussnoten
1) Ich hätte auch gerne MindsEye, Midjourney und natürlich Dall-e 2 getestet: Doch die ersten beiden Kunstmaschinen haben sich mir verweigert und für die zweite habe ich immer noch keine Einladung erhalten, trotz einer länger zurückliegenden Anmeldung. ↩
Beitragsbild: An old lady screaming at the sky (twiztidsmoke, starryai.com).
Danke für den Vergleichstest! Habe etwas mit Stable Diffusion experimentiert. Vorläufiges Fazit: Das Generieren von „Fotos“ ist extrem schwierig und man erkennt leicht Fehler. Viel besser geht das Erstellen von Malereien. „Venice painted by Van Gogh“, „Venice painted by Albert Anker“, „Venice painted by Pablo Picasso“ etc. führen zu wirklich eindrücklichen Resultaten. Auch erweiterte Anfragen wie „medieval painting of a city with a train passing by“ führen zumindest teilweise zu korrekten (im Sinne von „Zug fährt nicht auf Hausdach“) Resultaten.
Wir können vielleicht froh sein, dass es mit Fotos (noch) nicht funktioniert, das hätte viel mehr Missbrauchspotenzial als Malereien.
Dall-e 2 reiche ich gerne nach. Habe nach langer Wartezeit kürzlich die Einladung erhalten.
Girl: https://ibb.co/jR95JdL
Matterhorn: https://ibb.co/4SBcctX
Danke! Die werden gleich am Ende ergänzt!