Neulich habe ich über meine PHP-Querelen berichtet. Naja, «berichtet» ist womöglich nicht ganz das richtige Wort. Ich habe gejammert, was das Zeug hält. Weil es ärgerlich ist, wenn eine wunderbar funktionierende Website unvermittelt plötzlich aussieht, als sei sie von Parasiten befallen.
Als Webmaster ist man Kummer gewohnt…
Es geht um die von mir betreuten Website dorfposcht.ch. Sie ist bei Hostpoint untergebracht, und dort hat man anfangs Jahr PHP aufgerüstet. Neu ist dort PHP 5.6 der Standard. Bisher war es 5.4. Hostpoint hatte zwar per Mail über die Änderung informiert, nur hat mich dieses Mail nie erreicht¹.
Das neue PHP tut ein bisschen weh
Und selbst wenn es mich erreicht hätte, dann wäre mich wohl auf den «Who cares?»-Standpunkt gestellt. Denn eine Site, die mit PHP 5.4 brav läuft, wird mit PHP 5.6 auch keinen Ärger machen. Zumal mein wunderbares, selbstgebasteltes CMS² seit bald zehn Jahren brav seinen Dienst verrichtet.
Nun war das ein Trugschluss. Mit der neuen Version sah die Seite aus, als hätten Motten sich über sämtliche Umlaute hergemacht. Zusätzlich gab es diverse Fehlermeldungen³. Der Profi erkennt natürlich sofort ein Unicode-Problem. Und tatsächlich, PHP interpretiert die Textdateien der einzelnen Artikel als Unicode, obwohl die in meinem schönen CMS als Ansi mit westeuropäischer Codepage hinterlegt sind. Nun hätte man vielleicht diesen Standard ändern oder den PHP-Code anpassen können. Aber ich habe mich entschieden, das Problem zukunftssicher zu lösen und die Dateien in Unicode zu konvertieren.
Da das mehrere Tausend Dateien sind, wollte ich das nicht von Hand tun. Ich habe es erst mit dem im Beitrag Mass convert a project to UTF-8 using Notepad++ vorgestellten Script für Notepad++ (Das Textmonster) probiert⁴. Das führt rekursiv den Menübefehl Convert to UTF-8 without BOM aus. Falls man die deutsche Version der Software benutzt, muss man natürlich den Menübefehl anpassen. Ausserdem ist der Pfad (filePathSrc) und die zu ignorierenden Endungen entsprechend zu setzen.
Textdateien richtig codieren
Das Script hat eigentlich funktioniert, aber nicht hundertprozentig zuverlässig: Einige der konvertierten Dateien waren leer, was natürlich nicht im Sinn des Erfinders ist. Ich habe darum zu dem Programm UTFCast Zuflucht genommen. Das gibt es als Professional-Version für 47 Dollar oder als kostenlose Express-Variante. Und es macht genau das, was man erwartet: Es untersucht eine beliebige Anzahl von Textdateien auf ihre Codierung und wandelt sie bei Bedarf in Unicode um.
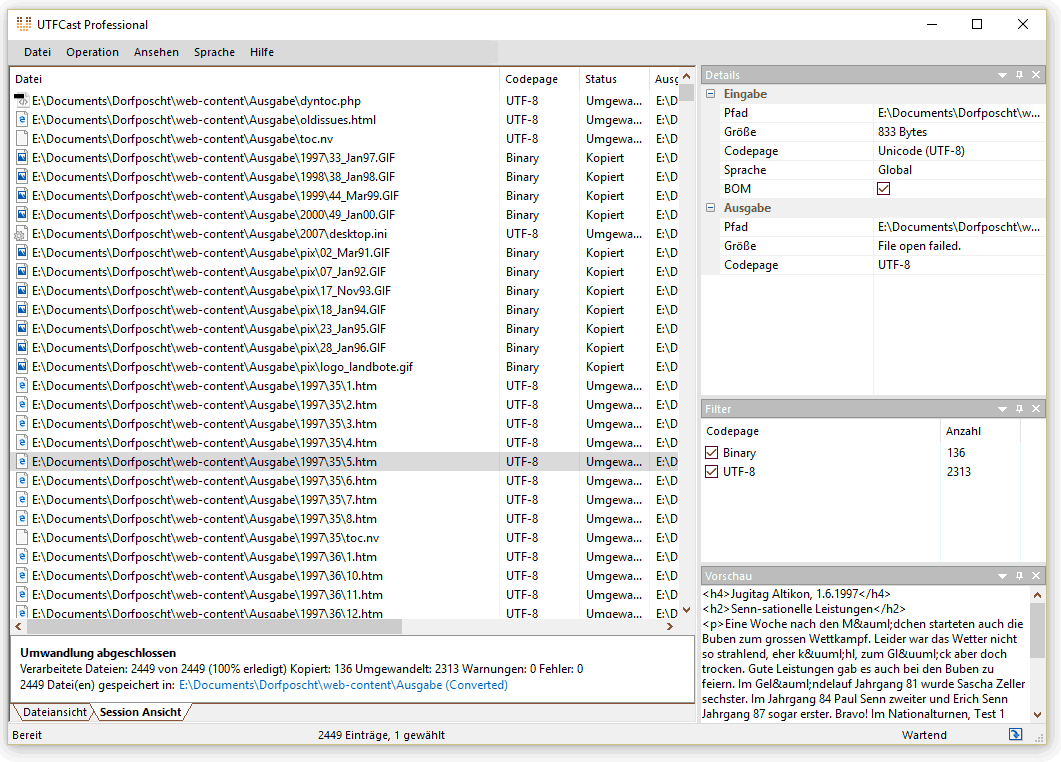
Das war schnell erledigt und hat mein Problem gelöst. Bis auf ein kleines Detail: Der obere Rand des Artikeltexts war nach der Konvertierung nicht mehr bündig mit der Navigationsleiste.
Ein seltsames Problem – denn wieso sollte die Codierung der Textdateien die Gestaltung der Seite beeinflussen? Das klingt einerseits unplausibel – und andererseits ist das Problem nicht so gravierend, als dass man es nicht einfach ignorieren könnte. Aber ich bin, was solche Dinge angeht, einfach ein Sturkopf: Einerseits will ich, dass die Seite so aussieht, wie ich das haben will. Und andererseits lässt es mir keine Ruhe, wenn ich mir ein solches Problem nicht erklären kann.
Was funktioniert hier nicht?
Ich habe darum ewig und drei Tage an meinen Stildateien herumgebastelt – hätte ja sein können, dass das Layoutproblem schon früher bestanden hatte und mir bloss nicht aufgefallen war. Aber nein, mit den CSS-Regeln war wirklich alles in Ordnung. Ausserdem hat ein Test mit einigen nicht konvertierten Dateien ergeben, dass mit denen alles im Butter ist.
Wie kann also Unicode schuld am Versagen der CSS-Regeln sein? Die Antwort liegt im BOM. Das ist eine unsichtbare Kennung am Anfang der Textdateien, die die Byte-Reihenfolge in der Textdatei angibt. Der Browser stellt diese Zeichen offensichtlich unsichtbar dar – das heisst, man sieht sie zwar nicht, aber sie bewirken einen zusätzlichen Leerraum am Anfang der Artikel.
Und tatsächlich: Wenn man sich im Netz umschaut, erhält man allenthalben den Tipp, seine Textdateien ohne BOM zu speichern. (So, wie das Notepad++-Script mir das auch nahegelegt hatte.) Mit UTFCast war dieses Problem rasant behoben – und der Umstieg auf die neue PHP-Version geschafft: Sogar Kompatibilität zu PHP7 ist hergestellt.
Und was lernen wir daraus? Webdesign ist etwas für Leute, die gern ein paar Stunden damit zubringen, dass hinterher alles wieder so aussieht wie vorher.
Fussnoten
1) Ja, ich habe die richtige Mailadresse hinterlegt. Und ja, ich habe auch im Spam-Ordner geschaut. ↩
2) «Das auf den wohlklingenden Namen PHP Page Butler hört, keinerlei Markenschutz geniesst und bislang leider auch kein Backend spendiert bekam.» ↩
3) Diese haben sich ohne mein Zutun in Luft aufgelöst…
import os;
import sys;
filePathSrc="C:TempUTF8"
for root, dirs, files in os.walk(filePathSrc):
for fn in files:
if fn[-4:] != '.jar' and fn[-5:] != '.ear' and fn[-4:] != '.gif' and fn[-4:] != '.jpg' and fn[-5:] != '.jpeg' and fn[-4:] != '.xls' and fn[-4:] != '.GIF' and fn[-4:] != '.JPG' and fn[-5:] != '.JPEG' and fn[-4:] != '.XLS' and fn[-4:] != '.PNG' and fn[-4:] != '.png' and fn[-4:] != '.cab' and fn[-4:] != '.CAB' and fn[-4:] != '.ico':
notepad.open(root + "" + fn)
console.write(root + "" + fn + "rn")
notepad.runMenuCommand("Encoding", "Convert to UTF-8 without BOM")
notepad.save()
notepad.close()